
Ten artykuł jest analizą domain ranking w kontekście tego jak ta tematyka przewija się na różnych grupach SEO powodując różnego rodzaju dyskusje. Właśnie dlatego zdecydowałem się zrobić mały test przy skorzystaniu z Machine Learningu, oczywiście przy wykorzystaniu Pythona oraz właściwych bibliotek jak Pandas czy Matplotlib.
Jak większość z nas wie przy pozycjonowaniu stron www jest wiele czynników, które są wzajemnie zależne, ale myślę, że bez problemów można poniekąd znaleźć wspólny mianownik.
Domain ranking
Nie chcę tu pisać, że jest to czynnik rankingowy używany przez Ahrefs itd. gdyż każdy zainteresowany to zapewne wie oraz rozumie. Jednak przy wielu konwersacjach w sieci, zauważyć można, że nadal są osoby co kładą duży nacisk na ten parametr i co najważniejsze, nie dają sobie przemówić do rozsądku, iż jest to tylko zewnętrzny czynnik.
Przeanalizowałem dosłownie jeden raport z Ahrefs, aby dowiedzieć się jak przy wykorzystaniu Pandas w Pythonie, można łatwo obalić mit ważności DR. Oczywiście ten tekst nie jest pisany pod SEO i są to tylko i wyłącznie moje analizy oraz badania nad tą kwestią. Nie jestem copywriterem aby nasycać ten artykuł frazami i zależy mi tylko i wyłącznie na pokazaniu co może dać nam głębsza analiza, aniżeli to co widzimy w Excelu czy patrząc tylko powierzchownie na raporty.
Przygotowanie środowiska
Pobrałem na początku jeden raport z Ahrefs z linkami przychodzącymi do danej strony www. Jak to raport zawiera on kilka niezbędnych danych i tylko nasza własna interpretacja tak naprawdę jest w stanie powiedzieć co w nim siedzi. Jeżeli chodzi o kwestie statystyczne:
- Liczba rekordów – 1129
- Wszystkie linki zwracają 200
- Język – głownie PL
- Platforma – różnie
Jednak to są dane, które tak naprawdę przy analizie danych odrzuciłem, oprócz kodu zwracanego nagłówka ponieważ błąd 404 jednak ma znaczenie. Chciałbym od razu napisać, że moja analiza jest moim zdaniem dość powierzchowna, lecz daje poniekąd wgląd w to, że domain rating nijako ma się do pozycji.
Czas na analizę pliku
Do badania wykorzystałem Pythona w którym w wolnych chwilach lubię się bawić oraz wykorzystując odpowiednie biblioteki do analizy danych jak Pandas.
Na samym początku zacząłem od importu Pandas, po uprzednim zainstalowaniu go globalnie na desktopie.
import pandas as pd
dane = pd.read_csv("link_do_pliku.csv", encoding='utf-16', sep="\t")
Niestety problemem jest to, że Ahrefs koduje pliki do UTF-16 i jako separator stosuje Tabulację to chwilę mi zajęło, aby dobrze to zdiagnozować.
Następnie chciałem mieć podgląd danych z jakimi przyjdzie mi pracować więc odpowiedni kod jak:
dane.describe()
dał mi tabelę z pierwszymi danymi:

Mając powyższe dane tak naprawdę miałem kilka możliwości:
-
Wykres Rozrzutu (Scatter Plot):
- Mogłem użyć wykresu rozrzutu, aby zbadać zależność między dwoma zmiennymi, na przykład między „Domain Traffic” a „Domain Rating”. To pomoże zobaczyć, czy istnieje jakaś korelacja między popularnością domeny a jej oceną.
-
Wykres Korelacji:
- Miałem wiele zmiennych numerycznych, mogłem stworzyć macierz korelacji i przedstawić ją za pomocą heatmapy. To pokaże, jak zmienne są ze sobą powiązane.
-
Histogramy:
- Histogramy są przydatne do zrozumienia rozkładu poszczególnych zmiennych, takich jak „Domain Rating” lub „Page Traffic”. Dzięki nim zobaczyć można, jak często pojawiają się różne zakresy wartości.
-
Wykres Pudełkowy (Box Plot):
- Wykres pudełkowy pomoże zrozumieć rozkład wartości dla danej zmiennej oraz zidentyfikować wartości odstające (outliers).
-
Wykres Słupkowy (Bar Plot):
- Jeśli posiadamy kategorie, na przykład różne grupy domen, wykres słupkowy może pokazać, jak różnią się one pod względem określonej zmiennej, np. średniego ruchu na stronie.
Jednak na samym początku zdecydowałem się na dość proste podejście, czyli przedstawieniu w wykresie słupkowym korelacji pomiędzy DR, a Reffering Domains. Przede wszystkim zależało mi na tym, aby mieć wiedzę, czy w jakikolwiek sposób są te dane ze sobą powiązane
Poniżej wykres to mi z tej analizy wyszło:
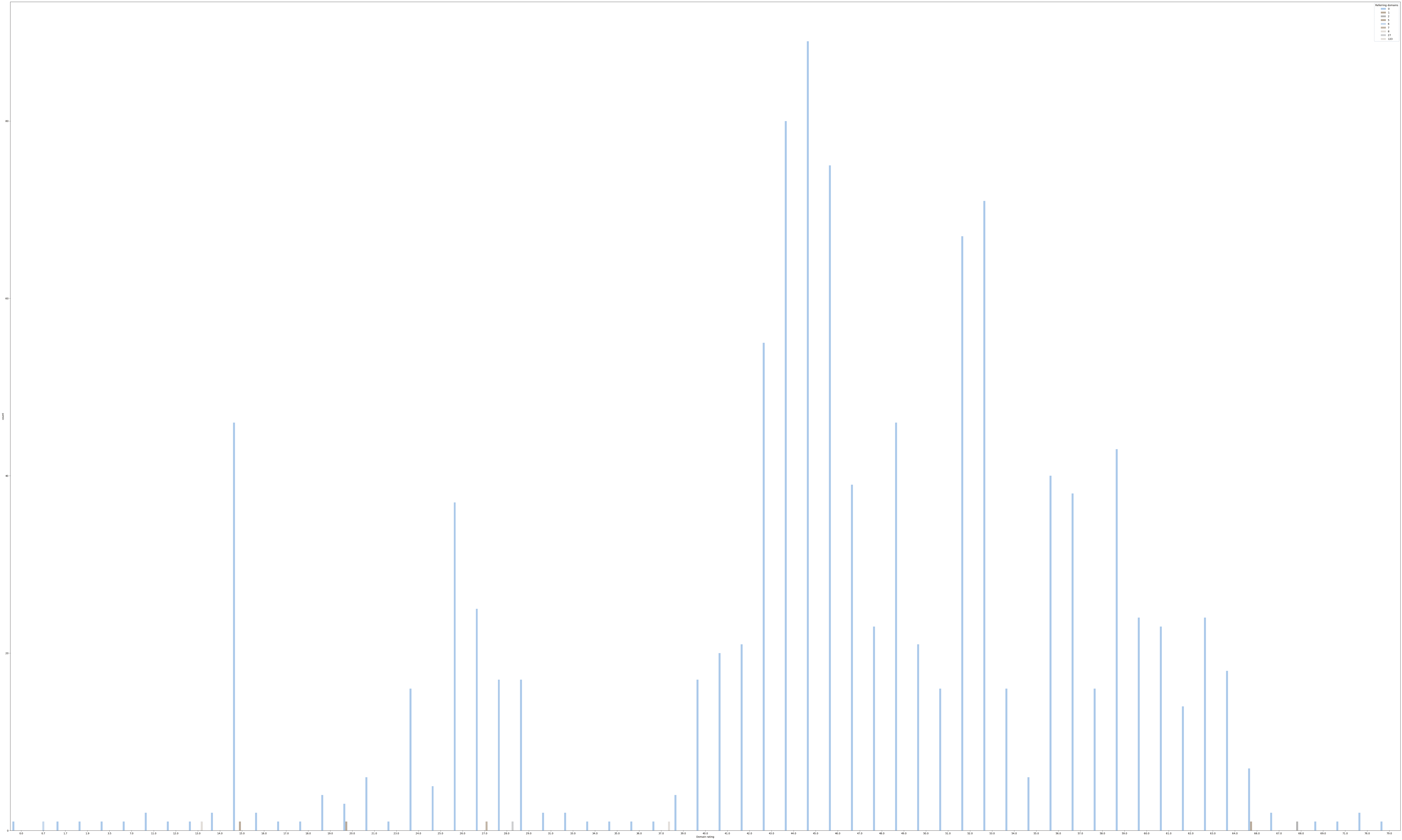
Wiem, że z tej perspektywy mało widać, ale jeśli chodzi o zależności to wychodzi na to, że domain rating (oś X) pomiędzy 40, a 66 był dla tej domeny najczęściej stosowany. Gdy mówimy od Reffering Domains (oś Y) to średnia wyniosła około 50 domen. Myślę, że nie trzeba nic tu więcej tłumaczyć, gdyż dane są dość oczywiste.
Kolejne dane
W przypadku kolejnych danych sytuacja ma się następująco. Chciałem mieć wiedzę ile danych zawiera każda kolumna więc dokonałem analizy:
dane.isna().sum()
Chodziło tu przede wszystkim o zsumowanie wszystkich możliwych danych występujących w danym pliku csv. Wynik jaki mi się ukazał i będzie on poddany dalszej analizie to:
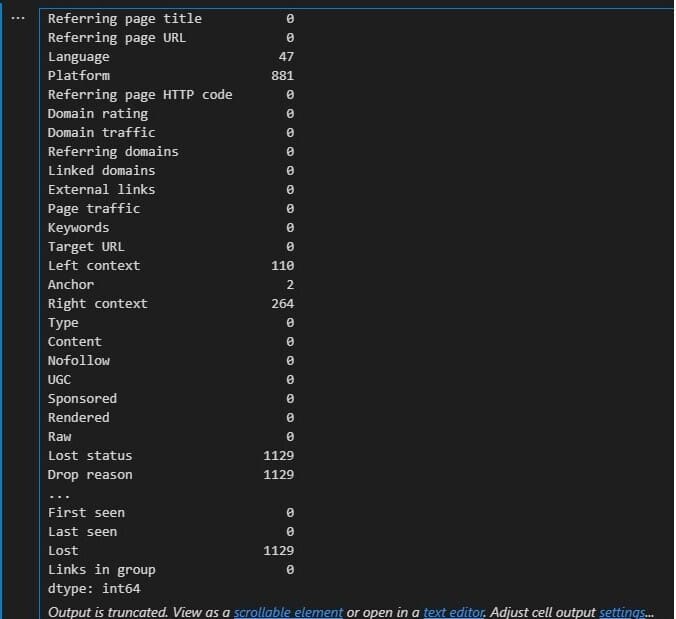
Z powyższego wynika to, iż nie ma co się przejmować kwestią Platform, Lost status, Drop reason. Jeżeli chodzi o całą resztę to przy analizie domain rating jak najbardziej ona wystarczy. Jak już pisałem wcześniej to jest to tylko i wyłącznie pobieżna analiza, aczkolwiek dająca już jakieś wnioski.
Domain rating i linkowanie
Jeżeli chodzi o kwestie linkowania to zależało mi na tym aby poznać 20 najbardziej wartościowych linków dla tej strony. W końcu link building jest niezwykle ważny. Dla tej strategii zastosowałem komendę:
pd.set_option('display.max_colwidth', 200)
dane_sorted = dane.sort_values(by='Domain traffic', ascending=False)
print(dane_sorted['Referring page URL'].head(20))
W tej sekcji specjalnie nie wyświetlę linków, gdyż nie chcę aby ktokolwiek pomyślał sobie źle na ten temat, Mianowicie korzystając nadal z Pandas w analizie SEO, można przyjąć, że najlepszymi linkami wg. analizy były katalogi stron oraz katalogi NAP. Do tego dochodzą jeszcze strony WEB 2.0 i tworzone jako kolejny Tier, witryny mające za zadanie wspomóc cały link building. Oto co otrzymałem:
Wizualizacja zależności
Finalnie zależało mi właśnie na tym, aby sprawdzić, czy domain rating ma jakiekolwiek powiązanie z ruchem z linkujących domen. Jak się okazało nie jest to nijako powiązane i DR jak jest średni lub wysoki, ale nie posiada wartościowego ruchu ponieważ:

Konkluzja 1
Jak zauważyłem witryna ta zajmuje bardzo wysokie miejsca na główne frazy kluczowe, które kierują ruch na stronę. Właśnie dlatego zdziwiłem się wynikami, gdyż mówi się o tym, aby nie patrzeć na domain rating jako wyznacznik gdyż jest to tylko i wyłącznie metryka zewnętrznego oprogramowania. Dodatkowo w ramach ciekawostki:
- 188 anchorów dla naked url
- Reszta anchorów to były: EMA, Partial anchor czy zero match anchor
Nie mogłem na tym poprzestać i zacząłem dalszą analizę, dzięki której uzyskałem zdecydowanie więcej danych.
Kolejna analiza znajduje się w tym artykule – Analiza linków SEO w Pythonie



